python 文件处理
目录:
一 引入

二 文件操作的基本流程
2.1 基本流程

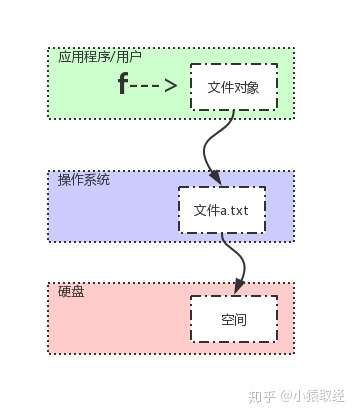
2.2 资源回收与with上下文管理

2.3 指定操作文本文件的字符编码

三 文件的操作模式
3.1 控制文件读写操作的模式
3.1.1 案例一:r 模式的使用
3.1.2 案例二:w 模式的使用
3.1.3 案例三:a 模式的使用
3.1.4 案例四:+ 模式的使用(了解)

3.2 控制文件读写内容的模式
3.2.1 案例一:t 模式的使用
3.2.2 案例二: b 模式的使用

四 操作文件的方法
4.1 重点

4.2 了解

五 主动控制文件内指针移动

5.1 案例一: 0模式详解

5.2 案例二: 1模式详解

5.3 案例三: 2模式详解

六 文件的修改

6.1 文件修改方式一
6.1 文件修改方式二

Last updated